Just trying not so confuse realistic testing with self-deception :) Not convinced testing with synthetic data can pretend to be similar to a production environment.
mapto
joined 9 months ago
It is not realistic to replicate a production setup in development when you're working with sensitive user data. I've worked in different contexts (law enforcement, healthcare, financial services) where we've had complicated setups (in one instance including a thing called pre-staging environment), but never would a sizeable team of developers have access to user data, and thus to a realistic setup in terms of size, let alone of quality of data.
I'm sorry, but doesn't sound very convincing. The strongest (reiterated) argument is "venv is standard", but so is docker.
Thanks, corrected
Thanks. I didn't know this and it is very useful information.
Even if so, your unreasonably pessimistic assumption is that this would be an exclusive source of revenue. Once content is created, cross-posting is free.
Thanks for doing the maths. Actually, it does show that there's a small, but unexploited market here. $2-3K a month is a very good income for the most of the world. And this doesn't have to be the only revenue stream.
Could you elaborate, please. I'm genuinely interested
Looks exciting, and the basic example in the user guide seems more intuitive than pandas. Looking forward to see how it's going to integrate with bokeh and plotnine, though.
I guess you misunderstood my providing illustrative examples in parentheses. Replace or remove the examples, the argument is still valid.
In another subthread they've pointed out that processing food also changes its protein density, most obviously by water transfer.
This is not a problem with the nutrition of foods, it is the metric that is poorly designed. One more argument against the chart
56
@kamilkazani on how a few Western corporations enable Russian arms manufacturing
(threadreaderapp.com)
I deploy a FastAPI service with docker (see my docker-compose.yml and app).
My service directory gets filled with files index.html, index.html.1, index.html.2,... that all contain
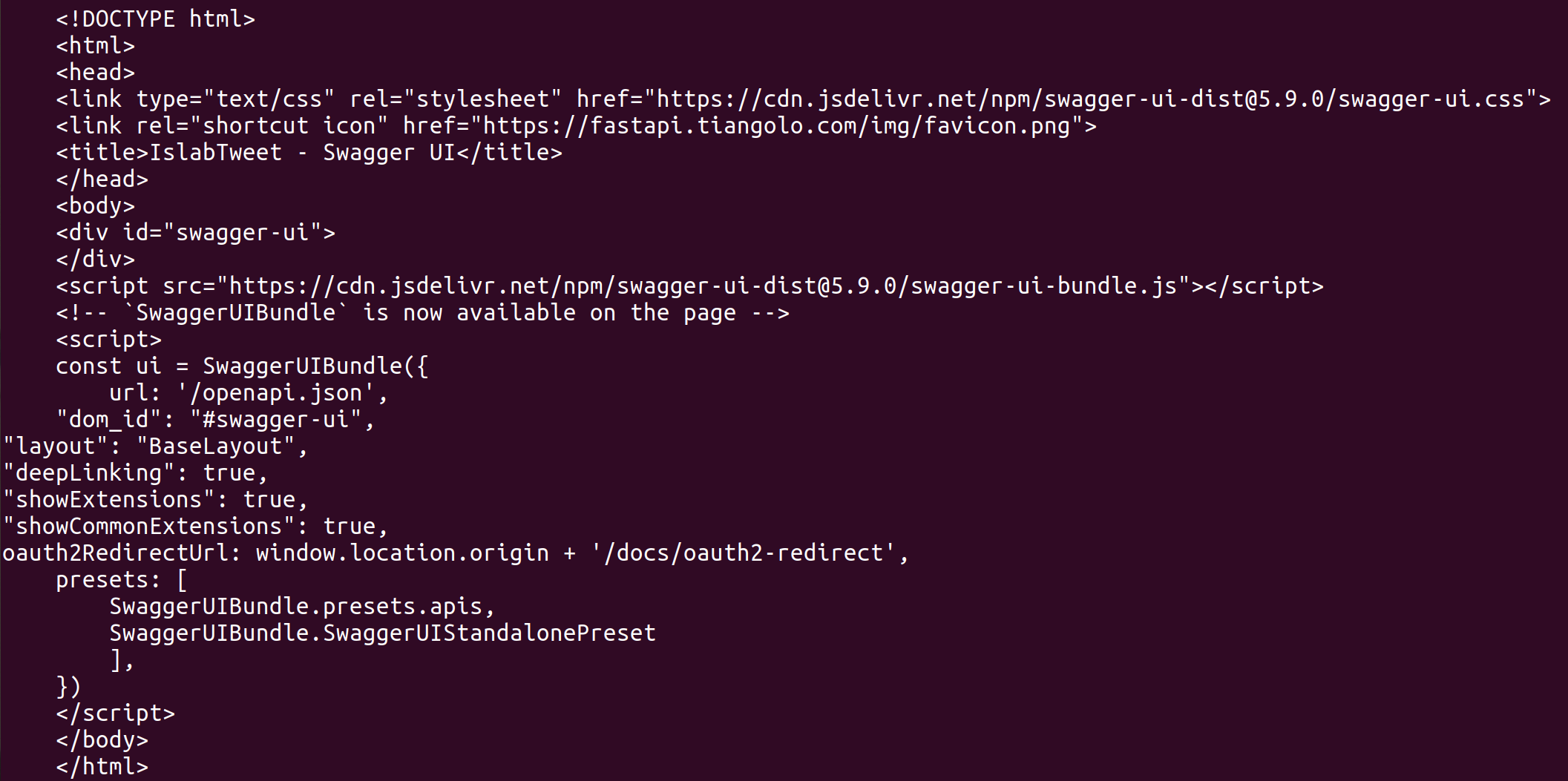
They seem to be generated any time the docker healthcheck pings the service.
How can I get rid of these?
PS: I had to put a screenshot, because Lemmy stripped my HTML in the code quote.
view more: next ›
I didn't realise. Was not paywalled for me on the phone.