It sounds like you're confusing the application with the data. Nothing in this model requires the use of production data.
danielquinn
joined 1 year ago
I feel like you must have read an entirely different post, which must be a failing in my writing.
I would never condone baking secrets into a compose file, which is why the values in compose.yaml aren't secrets. The idea is that your compose file is used exclusively for testing and development, where the data isn't real, and the priority is easing development. When you deploy, you don't use that compose file because your environment is populated by whatever you use in production (typically Kubernetes these days).
You should not store your development database password in a .env file because it's not a secret. The AWS keys listed in the compose are meant to be exactly as they are there: XXX, because LocalStack doesn't care what these values are, only that they exist.
As for the CLI thing, again I think you've missed the point. The idea is to start from a position of "I'm building images" and therefore neve have a "local app, (Django, sqlite)" because sqlite should not be used unless that's what's used in production. There should be little to no difference between development and production, so scripting a bridge between these doesn't make a lot of sense to me.
I don't mean to be snarky, but I feel like you didn't actually read the post 'cause pretty much everything you've suggested is the opposite of what I was trying to say.
- A CLI to make things simple sounds nice, but given that the whole idea is to harmonise the develop/test/deploy process, writing a whole program to hide the differences is counterproductive.
- Config settings should be hard-coded into your docker-compose file and absolutely not stored in
.jsonor.envfiles. The litmus test here is: "How many steps does it take to get this project running?" If it's more than 1 (docker compose up) it's too many. - Suggesting that one package Django into a single Lambda seems like an odd take on a post about Docker.
High praise! Just keep in mind that my blog is a mixed bag of topics. A little code, lots of politics, and some random stuff to boot.
It's a tough one, but there are a few options.
For AWS, my favourite one is LocalStack, a Docker image that you can stand up like any other service and then tell it to emulate common AWS services: S3, Lamda, etc. They claim to support 80 different services which is... nuts. They've got a strange licensing model though, which last time I used it meant that they support some of the more common services for free, but if you want more you gotta pay... and they aren't cheap. I don't know if anything like this exists for Azure.
The next-best choice is to use a stand-in. Many cloud services are just managed+branded Free software projects. RDS is either PostgreSQL or MySQL, ElastiCache is just Redis, etc. For these, you can just stand up a copy of the actual service and since the APIs are identical, you should be fine. Where it gets tricky is when the cloud provider has messed with the API or added functionality that doesn't exist elsewhere. SQS for example is kind of like RabbitMQ but not.
In those cases, it's a question of how your application interacts with this service. If it's by way of an external package (say Celery to SQS for example), then using RabbitMQ locally and SQS in production is probably fine because it's Celery that's managing the distinction and not you. They've done the work of testing compatibility, so theoretically you don't have to.
If however your application is the kind of thing that interacts with this service on a low level, opening a direct connection and speaking its protocol yourself, that's probably not a good idea.
That leaves the third option, which isn't great, but I've done it and it's not so bad: use the cloud service in development. Normally this is done by having separate services spun up per user or even with a role account. When your app writes to an S3 bucket locally, it's actually writing to a real bucket called companyname-username-projectbucket. With tools like Terraform, the fiddly process of setting all this up can be drastically simplified, so it's not so bad -- just make sure that the developers are aware of the fact that their actions can incur costs is all.
If none of the above are suitable, then it's probably time to stub out the service and then rely more heavily on a QA or staging environment that's better reflective of production.
You got the eyes just right!
Yeah that was the big strike against it for me too. I found that you can sort of perch it over a crossed leg and it's sort of serviceable that way, but yeah... no coding on the train with a Surface.
The Surface Pro keyboard is actually quite good, with the added bonus that it's also easily detachable.
This too is an excellent take. "Artificial pain points" for capitalism, or "learn some shit" for Linux. Love it.
At the firewall level, port forwarding forwards traffic bound for one port to another machine on your network on an arbitrary port, but the UI built on top of it in your router may not include this.
If it's not an option in your Fritzbox, your options are:
- Make the service running on your internal network listen on one of those high-number ports instead.
- Introduce another machine on the network that also performs NAT between your router and your machine
- Try to access the underlying firewall in your router to tweak the rules manually. Some routers have an admin console accessible via telnet or SSH that may allow this.
- Get a new router.
The first and last options on this list are probably the best.
You make an excellent point. I have a lot more patience for something I can understand, control, and most importantly, modify to my needs. Compared to an iThing (when it's interacting with other iThings anyway) Linux is typically embarrassingly user hostile.
Of course, if you want your iThing to do something Apple hasn't decided you should want to do, it's a Total Fucking Nightmare to get working, so you use the OS that supports your priorities.
Still, I really appreciate the Free software that goes out of its way to make things easy, and it's something I prioritise in my own Free software offerings.
I needed something for a presentation I'm doing on advanced Linux, so I thought something like this might be appropriate.
Annoyingly, I can't seem to get Bing to generate an image that isn't square.

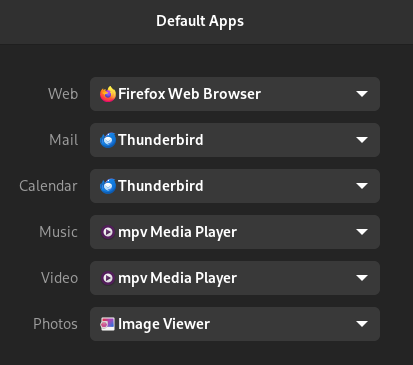
I'm working on a little program that'll launch different browsers based on the content of the URL passed and I'd like to set it as the default Web app in this list (under Settings → Default Apps). I've written a .desktop file based on the epiphany.desktop file, but it doesn't show up when I hit [Win]+o+p+e and it doesn't show up in the default apps either, so I'm hoping that someone here can explain what I've done wrong.
Here's the contents of the opening.desktop file:
$ cat ~/.local/share/applications/opening.desktop
[Desktop Entry]
Name=Opening
GenericName=Web Browser
Comment=Open links in the right browsers
Keywords=web;browser;internet;opening;
Exec=opening %u
StartupNotify=true
Terminal=false
Type=Application
Icon=/home/daniel/.local/share/applications/opening.png
Categories=Network;WebBrowser;
MimeType=text/html;application/xhtml+xml;x-scheme-handler/http;x-scheme-handler/https;multipart/related;application/x-mimearchive;message/rfc822;application/x-xpinstall;
Any criticisms are much appreciated!
view more: next ›
But there's nothing stopping you from loading realistic (or even real) data into a system like this. They're entirely different concepts. Indeed, I've loaded gigabytes of production data into systems similar to what I'm proposing here (taking all necessary precautions of course). At one company, I even built a system that pulled production into a developer-friendly snapshot while simultaneously pseudo-anonymising that data so it can be safely (for some value of ${safe}) be tinkered with in development.
In fact, adhering to a system like this makes such things easier, since you don't have to make any concessions to "this is how we do it in development". You just pull a snapshot from the environment you want to work with and load it into your Compose session.