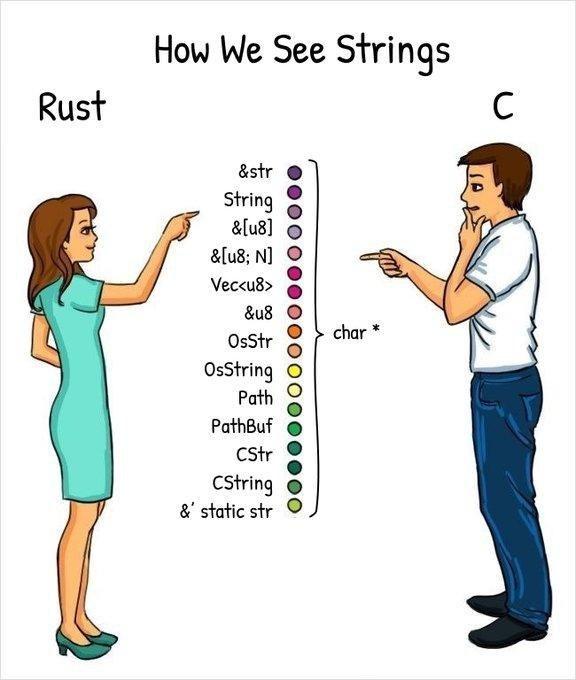
Fun fact: the standard neither defines the size or the signedness of char.
Post funny things about programming here! (Or just rant about your favourite programming language.)
Fun fact: the standard neither defines the size or the signedness of char.
All I see are pointers.
There is const char* that should be added to list.
As far as I remember, Win32 API (C-compatible C++) used to add more complexity: wchar_t*, LPSTR, LPCSTR, LPWSTR, LPCWSTR, LPTSTR, LPCTSTR as they preferred 16-bit strings over UTF-8. These were supposed to be independent safe ANSI/Unicode string wrappers. Sick.
I feel bad because I immediately knew what the abbreviations stand for -.-
wchar_t isn't from win32, but from ISO C. There should be a compatibility typedef/define called WCHAR in win32 headers for compilers that don't have wchar_t.
All those are ways of calling string in C? Why are there so many?
In Rust, and I don't know
Isn't it a bad thing?
Not necessarily a bad thing. If your method of invocation gives context about its possible use cases. You can make the program more safe because you know it's being used appropriately. If you're just passing a pointer around anything could happen to it. So it's hard to help the programmer not make mistakes
The String vs. &str split is definitely annoying, but a necessary drawback of Rust's ownership mechanics (which bring many benefits compared to C in other places).
The others have their specific use-cases (like file paths or C interop). It's certainly not like you constantly juggle 8 different kinds of strings.
The primary reason there are so many ways is the Rust ownership and type system.
String is a 'normal' mutable UTF-8 string that is allocated on the heap.&str is either a slice reference pointing to a part of a string or a string literal in read-only memory.&[u8] is a reference to slice of bytes (so only capable of ASCII characters).&[u8; N] is a reference to a fixed size slice reference of bytes where the length is encoded in the type.Vec<u8> is a mutable array of bytes (the former two are immutable in contrast).&u8 is a reference to a single byte.OsString is an owned, mutable platform native string in the platform's preferred representation (e.g. non-zero byte UTF-8 on Linux, non-zero byte UTF-16 in Windows).OsStr is a borrowed version of an OsString.Path is a slice that supports operations like obtaining the root element or file name or check if it is absolute or relative or to check if the the file exists in the file system.PathBuf is an owned, mutable version of the former one.CString is an owned representation of a string that should be compatible with C (e.g. null terminated and no zero bytes in between). They are handy if you want to call C libraries from Rust code.CStr is a borrowed version of CString.&'static str is a string slice reference with a static lifetime and is therefore valid for the duration of the entire program (in contrast to slices of Strings that might get de-allocated at some point).&u8 is a reference to a single byte.
I'm not sure this meme really cares to make perfect sense, but I don't think that's ever useful...?
A single byte is going to be smaller than a pointer address, so you can just copy the u8 without loss of efficiency.
Good explanation. However, OsString is not necessarily valid UTF-8/UTF-16 (in thay case, it could simply be String). The docs describe it pretty well.